Restore di un database SQL Server in un container Docker
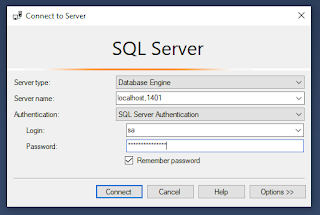
Qualche giorno fa un collega aveva la necessità di eseguire il restore di un database creato con Microsoft SQL Server 2016 in locale, in modo da poter eseguire la creazione di una dashboard in PowerBI. La nostra scelta di team - ormai da anni - è stata quella di installare sui nostri computer meno strumenti possibili, e solo quelli essenziali per portare avanti il lavoro quotidiano. Meno strumenti su un computer = meno spazio disco consumato = più risorse disponibili; quindi la scelta è sempre quella di appoggiarci a risorse ospitate in cloud . In questo caso lo scenario era più complesso, e il semplice restore del nostro backup di database nel cloud, non sembrava essere la soluzione più performante, specialmente per via dell'obiettivo che avevamo - ovvero un' analisi dei dati - in un ambiente di sviluppo. Quindi quello che ho cercato di fare è semplicemente prendere il backup in questione - che nel nostro esempio sarà il file test.bak - ...

